DeepSeek“低调”扔了版更新 性能跃升引猜测

中国人工智能初创公司深度求索(DeepSeek)于3月24日深夜低调上线了新版本DeepSeek-V3-0324,参数量达到6850亿。该版本在代码、数学和推理等多个方面的能力显著提升,尤其是代码能力已经接近美国Anthropic公司的大模型Claude 3.7。
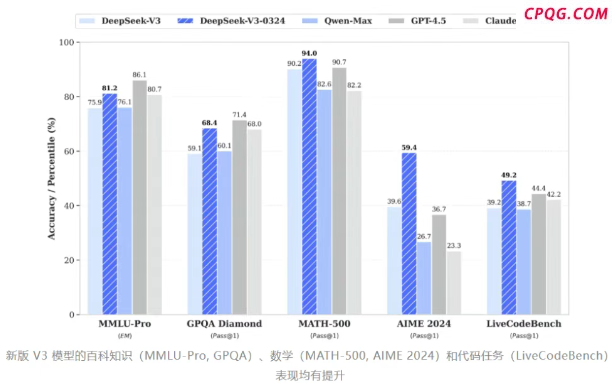
外界对DeepSeek-V3-0324的关注不仅在于其能力提升,还猜测这是否预示着更新一代的V4与R2大模型即将发布。据DeepSeek介绍,新版本的主要改进包括:代码能力显著增强,能够一次性生成800行无错误的网页代码,并实现动态响应式布局和交互效果;数学与逻辑推理能力也有所提高,部分表现接近专业推理模型;此外,V3-0324采用MIT许可证,允许自由修改、分发及商业化应用,降低了开发者的使用门槛。
清华大学新闻学院和人工智能学院教授沈阳表示,DeepSeek-V3-0324不仅是V3系列的一次迭代,也是中国AI技术崛起的重要标志。其在性能、效率和开源策略上的综合优势使其在全球大语言模型领域占据重要地位。未来,DeepSeek可能通过进一步提升推理能力和扩展多模态功能来巩固技术领先优势,同时在中美竞争和社区生态中寻找平衡点。尽管这次更新看似是一次“小更新”,但其性能跳跃表明该团队可能在为后续重大版本做准备。
路透社今年2月底报道,DeepSeek原计划在今年5月初发布R2,但现在希望尽早推出,具体时间尚未透露。DeepSeek希望新模型在代码生成和多语言推理方面的表现进一步提升。不过,这些传言没有得到DeepSeek公司的证实或回应。
沈阳指出,DeepSeek-V3-0324的推出进一步凸显了中国AI企业在技术和成本上的竞争力。美国对中国GPU出口限制可能促使中国企业加速国产硬件适配,同时其开源模式可能会引发西方厂商的连锁反应,例如推出更强的闭源模型。他认为2025年可能是中美AI竞争的关键节点。
在OpenAI公司计划将通用大模型和推理大模型融合在一起的背景下,外界关注包括DeepSeek在内的中国头部大模型是否会跟随这一趋势。沈阳认为这种可能性存在,因为用户更关心的是大模型能否提供更为智能和合理的参考答案,而不关心具体使用的模型类型。

版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:http://www.cpqg.com/html/xinwen/chuangyezixun/1611.html